- Bundling front-end and adding compilation (you are here!)
- Decreasing front-end size and improving caching
- Speeding up build and improving the development workflow
Want to stay tuned for the future posts? Subscribe
What is webpack#
Webpack is a front-end bundler. And a front-end bundler is a tool that combines multiple modules into a single file called bundle:
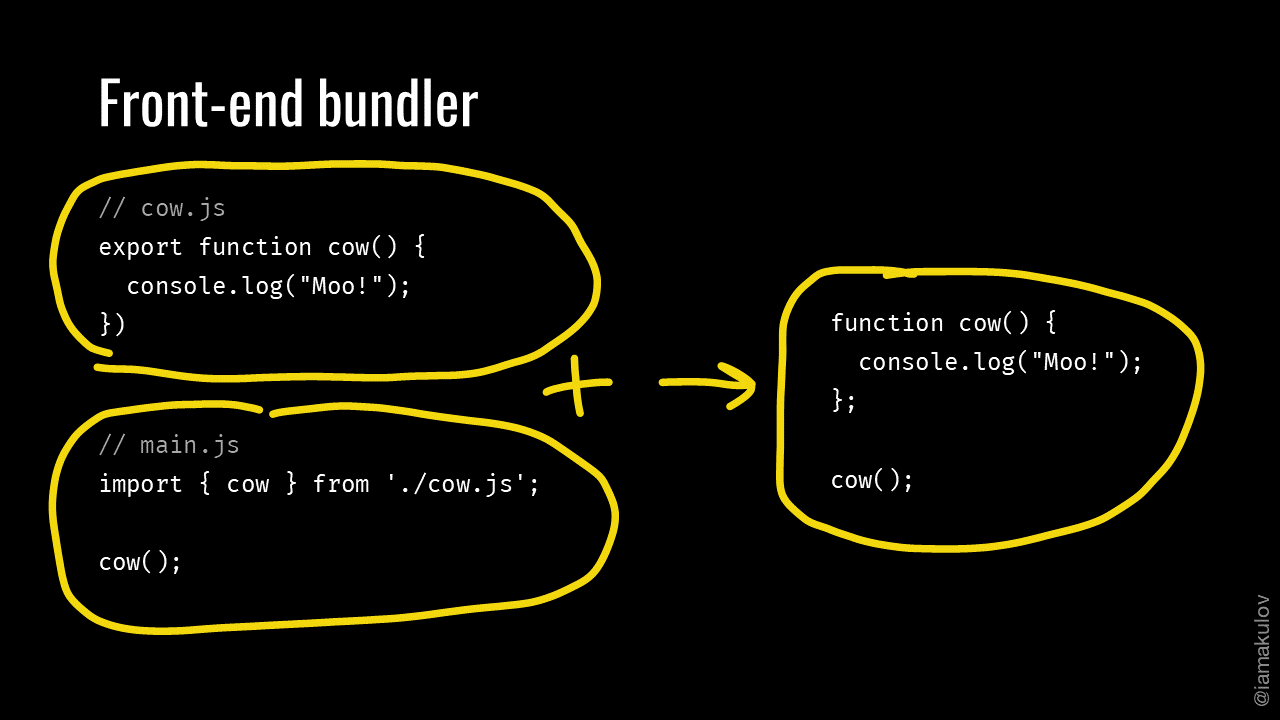
While the main purpose of webpack is bundling, it also has a lot of other abilities. For example, webpack can compile your front-end, split your code into multiple files or optimize your bundle size. I’m reviewing many of these abilities in this series of posts.
If you’re not familiar with the concept of bundling, Preethi Kasireddy wrote a good introduction to it. Check it out and come back!
Task Bundle front-end#
Given: you have an application that consists of lots of modules. Like Cut the Rope:

You want to bundle the modules into a single file: to speed up the loading of an app*, or to serve a library as a single module, or for another reason. Let’s see how webpack can help with this.
* – if you’re thinking “Wait, HTTP/2 made bundling unnecessary”, see the Khan Academy’s post about why no bundling is a bad idea
Good case: your code uses a popular module system#
// comments.js
define(['./dist/lodash.js'], (_) => {
// …
return { … };
});
// index.js
define(['./comments', …], (comments, …) => {
// …
comments.render(commentsData, '#comments');
});
If your code uses AMD, CommonJS or ES modules, everything is simple. Webpack supports these module systems out of the box, so to compile a project with them, you’ll only need to specify the entry file and the name of the resulting file.
To do this, create a file called webpack.config.js in the root of your project with the content like this:
// webpack.config.js
module.exports = {
// An entry point. It’s the main module of your application
// that references all the other modules
entry: './src/index.js',
output: {
// The directory where the bundle should be placed
path: './dist',
// The name of the resulting bundle
filename: 'bundle.js',
},
};
Then, run webpack:
npm install --global webpack
cd your/project/directory
webpack
Once you launch webpack, it will compile your project and generate a bundle with all your JavaScript. What’s left? Replace the import of your old entry file with the name of the new file:
// index.html
<!doctype html>
<body>
<!-- … -->
- <script src="./src/index.js"></script>
+ <script src="./dist/bundle.js"></script>
</body>
Task solved.
Bonus point: all module types at once#
Webpack supports all three module types in the same project simultaneously. So if a part of your code is in AMD and the other part is in ES modules, it will just work. This can be helpful if you decide to gradually migrate from one module format to another.
Bad case: your code uses your own module system#
// comments.js
MyApp.define(['./dist/lodash.js'], (_) => {
// …
return { … };
});
// index.js
MyApp.define(['./comments', …], (comments, …) => {
// …
comments.render(commentsData, '#comments');
});
In case your code uses a module system different from AMD, CommonJS or ES modules, things get more complicated. To make webpack work with your code:
- either migrate your code to a supported module format. Facebook has a tool called codemod which can automate a massive refactoring and could be useful for you;
- or write a Babel plugin for converting your custom module format to AMD, CommonJS or ES modules. This plugin will be executed on each compilation. Take a look at babel-plugin-transform-amd-to-commonjs to get an idea of how to write it. (We’ll see how to enable Babel a bit later.)
After you deal with the custom module format, configure the entry point and the output as described in “Good case” above.
Bonus point: global webpack installation#
Although installing webpack globally (
// package.json
{
"scripts": {
"build": "webpack"
}
}
# Console
npm run build
Task Compile JavaScript#
Given: you have some code that cannot be run in the browser. This can be code that uses features from the next JavaScript standard or even code in another language like TypeScript:
// comments.js
import _ from 'lodash';
export async render(…) {
const userData = await getUserData(userId);
// …
}
You want to compile it to make it work. Let’s see how webpack helps to solve this task.
Assume you’re using Babel. You may have used it from the command line specifying the input and the output:
babel ./src -d ./dist
Or you may have used it from Gulp as a part of a stream:
gulp.task('default', () => {
return gulp.src('./src/**/*.js')
.pipe(babel())
.pipe(gulp.dest('dist'));
});
webpack has a bit different approach. It uses loaders.
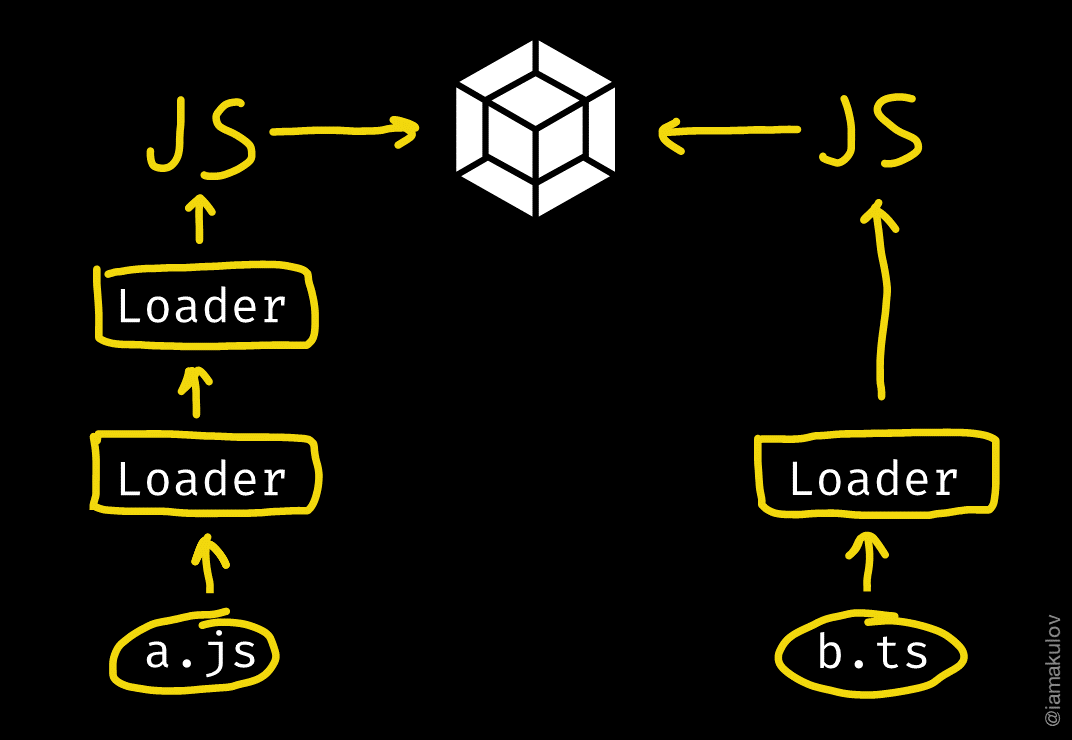
A loader is a JavaScript module. Webpack pipes all files through specified loaders before adding them into bundle.
A loader accepts any input and converts it to JavaScript which webpack works with. Loaders can be organized into chains; a chain accepts any input, pipes it through the loaders and passes the result to webpack. In this case, intermediate loaders can return anything, not only JavaScript.
In webpack, Babel works as a loader. To use it, install babel-loader with its peer dependencies. Then, tell webpack to apply the loader with the module.rules option:
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
{
// Take every JavaScript file imported into a bundle...
test: /.js$/,
// ...and pipe it through babel-loader...
use: ['babel-loader'],
// ...with the following options
options: {
presets: ['env'],
},
},
],
},
};
The same approach works for TypeScript:
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
{
test: /.ts$/,
use: ['ts-loader']
}
]
}
};
Or you can chain Babel and Typescript to do transformations that aren’t supported by the latter:
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
{
test: /.ts$/,
// Loaders are applied from right to left
use: ['ts-loader', 'babel-loader']
}
]
}
};
You can find the list of the most popular loaders in webpack docs.
Bonus point: different ways to specify a loader#
Above, I passed a string array into the use property to apply a loader. There’re two more ways to specify loaders. Here’re all of them:
// Specifies a single loader with or without options
{
test: /.js$/,
loader: 'babel-loader',
options: { ... }
},
// Specifies multiple loaders without options
{
test: /.ts$/,
use: ['ts-loader', 'babel-loader']
},
// Specifies multiple loaders with or without options
{
test: /.ts$/,
use: ['ts-loader', { loader: 'babel-loader', options: { ... } }]
}
Choose between them based on your needs.
Bonus point: loaders in the require query#
Apart from specifying loaders in webpack.config.js, you can also specify them in your import request:
import comments from 'ts-loader!babel-loader?presets[]=env!./comments.ts';
This can be useful for testing. Nevertheless, I don’t recommend using it in production because it makes your code dependent on a specific bundler.
Task Manage other files#
Webpack can also help you manage your styles, images or any other files.
Given: front-end application with styles and other assets.
You want to manage them with webpack to reduce the number of the necessary tools. Let’s see how to do this.
The one important thing you should remember here is the following:
That is. In a traditional task manager like Gulp you split your front-end compilation by a file type:
// gulpfile.js
gulp.task('js', function () {
return gulp.src('./src/index.js')
// ...
.pipe(gulp.dest('./dist/'));
});
gulp.task('css', function () {
return gulp.src('./src/**/*.scss')
// ...
.pipe(gulp.dest('./dist/'));
});
In webpack, however, you don’t split the compilation. You treat the front-end as a whole single thing. To include styles and other assets, you import them:
// comments.js
import _ from 'lodash';
import './comments.scss'; * ← Here
import iconUrl from './commentsIcon.svg'; * ← And here
export function render() {
// ...
}
and apply specific loaders to teach webpack to handle these imports. Imported files either get inlined into the bundle or placed next to it. This depends on the loader you use.
Let’s see how to use this in practice.
Q: For the mother of god, why?#
A: I don’t know why it was decided like this in the beginning. Nevertheless, this brings a real benefit. Usually, with webpack, you import all files used by a component straight into its main JS file. Because of this, all these files will be included into your bundle only if you actually use the component in your app.
Styles#
Here’s the most basic approach:
// comments.js
// Import the file to pass it under webpack’s management
import './comments.css';
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
// Configure webpack to pass all .css files through css-loader and style-loader
// (remember that loaders are applied from right to left)
{ test: /.css$/, use: ['style-loader', 'css-loader'] },
],
},
};
Here’s what the loaders do:
- css-loader reads the CSS file, passes all @import and url() in that file through webpack and returns the result,
- style-loader gets the passed CSS content and creates code that will append that CSS to <head> when the bundle gets loaded.
If you need to compile your styles with a preprocessor, append a corresponding loader into the loaders list and pass the importLoaders = 1 option to css-loader:
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
{ test: /.css$/, use: [
'style-loader',
{ loader: 'css-loader', options: { importLoaders: 1 } },
'sass-loader',
] },
],
},
};
See: postcss-loader, sass-loader, less-loader.
Bonus point: CSS Modules#
In the examples above, styles don’t provide any exports and therefore are just imported. However, there’s no technical limitation to provide exports, so there are approaches that do this. One of them is CSS Modules.
With CSS Modules, importing a stylesheet returns a JavaScript object with class names specified in the file. These class names are converted to be unique, so you can use a class name like .button in several components without any collision:
/* button.css */
.button { /* styles for the normal state */ }
.disabledButton { /* styles for the disabled state */ }
.errorButton { /* styles for the error state */ }
// button.js
import styles from './button.css';
buttonElement.outerHTML = `<button class=${styles.button}>Submit</button>`;
CSS Modules are enabled by passing the modules = true option to css-loader. Read more in the CSS Modules introduction.
Other files#
All the other files are also managed using loaders. Approach for every file type is different, so find the appropriate loader and look into its docs. See the list of the most popular loaders.
Here’re examples of loaders for different file types:
-
import iconDataUrl from './icon.svg'; // => iconDataUrl contains a data url of the icon -
import template from './template.pug'; // => template is a function that returns // the rendered HTML -
import documentUrl from './document.pdf'; // => document.pdf is emitted next to the bundle; // documentUrl is its public URL
Σ#
The key points:
- The minimal config of webpack is just the entry point and the output file. Webpack works with AMD, CommonJS and ES modules out of the box
-
You can use loaders to compile your JavaScript and manage other front-end files
-
Every file is imported as a module
See the second part, “Decreasing front-end size and improving caching”
The third part of the guide, “Speeding up build and improving the development workflow”, is coming soon. Leave your email to know when it’s out:
(you’ll receive an email about the next part of the guide + a couple of more webpack-related posts if I write them; no spam)
Thanks to Artem Sapegin for reviewing this post