This is the second part of a three-part introduction into webpack:
- Bundling front-end and adding compilation
- Decreasing front-end size and improving caching (you are here!)
- Speeding up build and improving the development workflow
Want to stay tuned for the future posts? Subscribe
Last updated on 21 Jan 2018: replaced the recommended plugin in the Moment.js part.
Task Decrease front-end size#
Given: you have a front-end application. You want to decrease its size to make it load faster.
Let’s see how webpack can help with this.
Minification#
Minification is when you compress your code by removing extra spaces, shortening variable names, etc. Like this:

Webpack has two approaches to minify the code: the UglifyJS plugin and loaders options. They should be used simultaneously.
The UglifyJS plugin works on the level of the bundle and compresses it after compilation. As you might’ve guessed, it used UglifyJS under the hood. This is how it works:
You write code like this
// comments.js
import './comments.css';
export function render(data, target) {
console.log('Rendered!');
}
↓
Webpack compiles it into approximately the following
// bundle.js (part of)
"use strict";
Object.defineProperty(__webpack_exports__, "__esModule", { value: true });
var __WEBPACK_IMPORTED_MODULE_0__comments_css__ =
__webpack_require__(4);
var __WEBPACK_IMPORTED_MODULE_0__comments_css___default =
__webpack_require__.n(__WEBPACK_IMPORTED_MODULE_0__comments_css__);
__webpack_exports__["render"] = render;
function render(data, target) {
console.log('Rendered!');
}
↓
The UglifyJS plugin minifies it into approximately the following
// bundle.js (part of)
"use strict";function r(e,t){console.log("Rendered!")}
Object.defineProperty(t,"__esModule",{value:!0});
var o=n(4);n.n(o);t.render=r
To enable the plugin, add it to the plugins section of the config:
// webpack.config.js
const webpack = require('webpack');
module.exports = {
plugins: [
new webpack.optimize.UglifyJsPlugin()
]
};
The second approach is loaders options. It allows compressing things that UglifyJS can’t minify. Its point is that some code (e.g. CSS that you import) is compiled as a string which UglifyJS can’t handle:
/* comments.css */
.comment {
color: black;
}
↓
// bundle.js (part of)
exports = module.exports = __webpack_require__(1)();
exports.push([module.i, ".comment {\r\n color: black;\r\n}", ""]);
To minify it, you should configure the loader. Here’s how you do it with css-loader:
// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: [
'style-loader',
{ loader: 'css-loader', options: { minimize: true } }
]
}
]
}
};
Pitfall: ES2015 code#
UglifyJS 2 (which is used in webpack) can’t compile ES2015+ code. This means that if your code uses classes, arrow functions or other new language features, and you don’t compile it to ES5, UglifyJS won’t handle it. In this case, you can use Babili, a Babel-based minifier. See babili-webpack-plugin
NODE_ENV=production#
Another way to decrease the front-end size is to set NODE_ENV environmental variable to the value “production”.
NODE_ENV is an environmental variable that is commonly used in libraries to detect in which mode the library works – in development mode or on a production server. The library can behave differently based on this variable. For example, React does additional checks and prints warnings when it’s built for development:
// …
if (process.env.NODE_ENV !== 'production') {
validateTypeDef(Constructor, propTypes, 'prop');
}
// …
When you’re building your app for production, it’s better to also tell that your libraries. For Node.js libraries, it’s done by configuring the environment and setting the NODE_ENV variable to “production”. For front-end libraries, it’s done by replacing process.env.NODE_ENV with a specific value:
// webpack.config.js
const webpack = require('webpack');
module.exports = {
plugins: {
new webpack.DefinePlugin({
'process.env.NODE_ENV': '"production"'
})
}
};
DefinePlugin takes an object with keys referring to variables to be replaced and values referring to the values that should be substituted. With this configuration, it’ll replace all process.env.NODE_ENV instances with "production", which will make UglifyJS understand that the comparison expression is always false and remove it:

ECMAScript imports#
The next way to decrease the front-end size is to use ECMAScript imports and exports.
When you use ECMAScript imports and exports, webpack becomes able to do tree-shaking. Tree-shaking is when a bundler traverses your whole dependency tree, checks what of them are used, and keeps only the used ones. So, if you use ECMAScript module syntax, webpack can eliminate the unused code:
You write two files where only one export is used
// comments.js
export const commentRestEndpoint = '/rest/comments';
export const render = () => { return 'Rendered!'; };
// index.js
import { render } from './comments.js';
render();
↓
Webpack realizes that commentRestEndpoint is not used and doesn’t generate a separate export point in the bundle
// bundle.js (part of)
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
/* unused harmony export commentRestEndpoint */
/* harmony export */__webpack_exports__["b"] = render;
var commentRestEndpoint = '/rest/comments';
var render = function () { return 'Rendered!'; }
})
↓
UglifyJS removes the unused variable
// bundle.js (part of)
(function(n,e){"use strict";e.b=r;var r=function(){return"Rendered!"}})
This works even with libraries; the library should also be written with ECMAScript modules.
Pitfall: tree-shaking doesn’t work without UglifyJS#
The less-known fact is that the unused code is removed not by webpack, but by UglifyJS. Webpack just removes export statements for the exports that aren’t used, which makes them possible to be removed by a minifier. Therefore, if you compile your bundle without the minifier, the bundle won’t get smaller.
See how to enable UglifyJS in the “Minification” section.
If you use Babel with babel-preset-env or babel-preset-es2015, check the settings of these presets. By default, they transpile ECMAScript’s import and export to CommonJS’ require and module.exports. Pass the { modules: false } option to disable this:
// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: [{'babel-loader', options: {
presets: [['es2015', { modules: false }]]
}]
}
]
}
};
Pitfall: complex cases aren’t optimized#
In some complex cases – e. g. when you re-export something (export * from 'file.js'), or when you compile classes with the TypeScript compiler – webpack can’t optimize your bundle. The bad things about this are that the cases when this happens aren’t obvious, and it’s unclear when this will be fixed. Here’s the corresponding GitHub issue: webpack/webpack#2867
Webpack team is working on a solution for re-exports though.
Moment.js#
Tested with moment.js 2.18.1
Moment.js is a library for working with dates. By default, when you include it in your app, it takes 217 kB of minified code. That’s huge – the average size of JavaScript on a page was 417 kB in April 2017. The good part, however, is that it can be easily reduced.
165 kB of the size of moment.js is localization files. They’re included even if you don’t use them. This happens because moment.js chooses the localization files dynamically, during runtime:
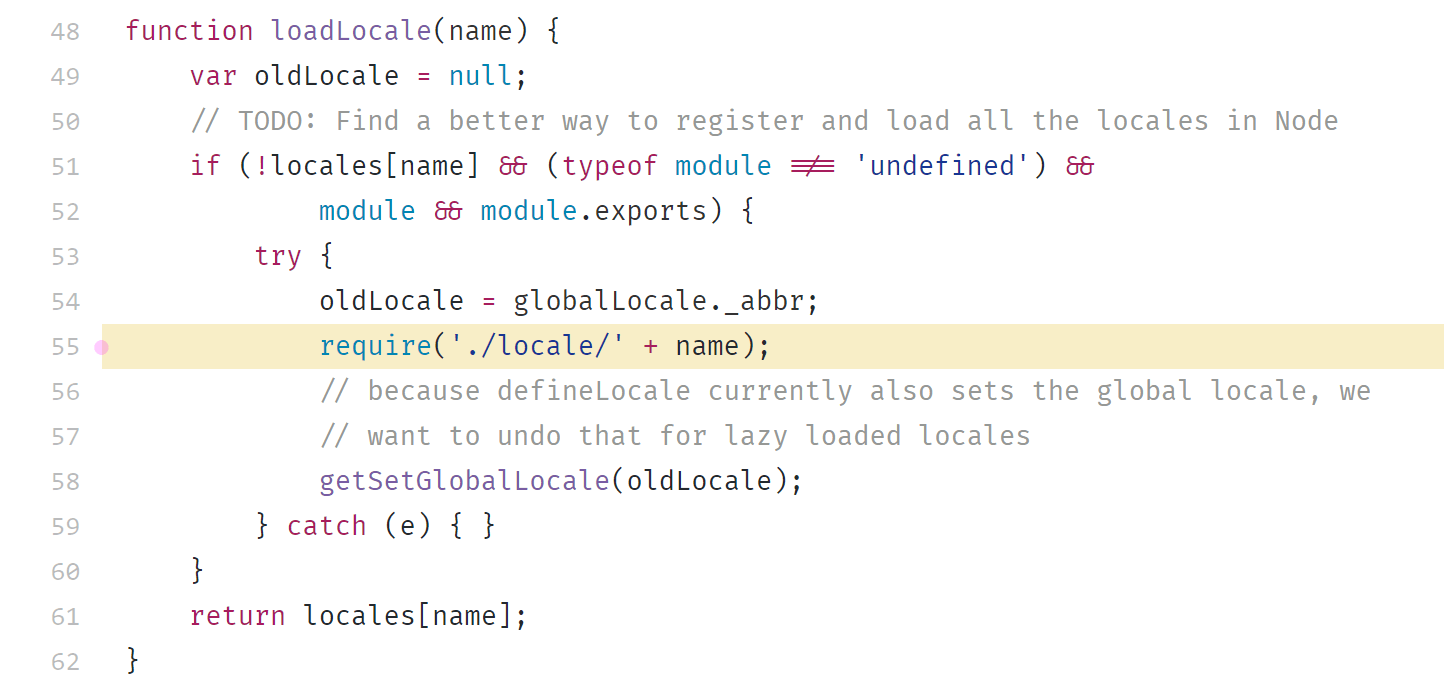
Webpack doesn’t know which files you’ll need, so it includes all files from the locale directory.
To deal with it, specify the exact files with MomentLocalesPlugin:
// webpack.config.js
const MomentLocalesPlugin = require('moment-locales-webpack-plugin');
module.exports = {
plugins: [
// Or: To strip all locales except “en”, “es-us” and “ru”
// (“en” is built into Moment and can’t be removed)
new MomentLocalesPlugin({
localesToKeep: ['es-us', 'ru'],
}),
],
};
Lodash#
Lodash is a collection of JavaScript utilities.
Tested with Lodash 4.17.4
When you include Lodash, your bundle grows by 72 KB of minified code. That’s the size of all the 316 Lodash methods. If you use only, like, 20 of them, then approximately 65 KB of the code do just nothing except slowing down the page loading.
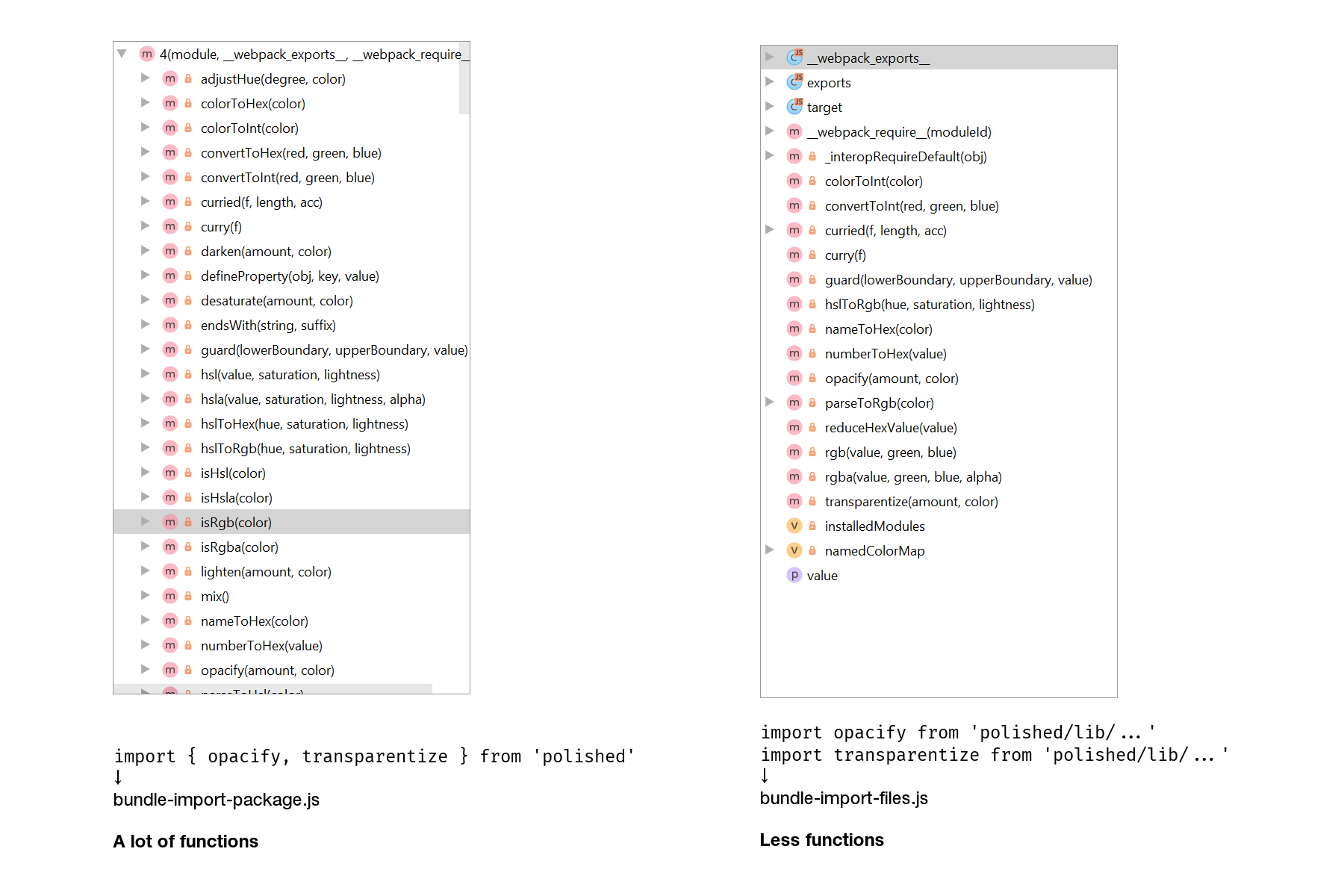
Thankfully, Lodash lets you include only the methods you need. The most basic way to do this is to import methods from the files they’re implemented in:
72 KB → 8.27 KB
- import _ from 'lodash';
- _.get();
+ import get from 'lodash/get';
+ get();
This approach might work if you’re starting a project from scratch, but it doesn’t work for existing projects. What you’re gonna do, rewrite all imports? That’s too much work. That’s why I prefer using babel-plugin-lodash and sometimes lodash-webpack-plugin.
babel-plugin-lodash is a plugin for Babel that replaces generic imports with concrete ones during compilation. That is, it does exactly the same thing as depicted in the snippet above:
72 KB → 8.27 KB
// Before babel-plugin-lodash
import _ from 'lodash';
_.get({ a: { b: 5 } }, 'a.b');
↓
// After babel-plugin-lodash
import _get from 'lodash/get';
_get({ a: { b: 5 } }, 'a.b');
lodash-webpack-plugin is a plugin for webpack that modifies Lodash behavior by removing some code and thus cutting the bundle size. For example, _.get by default supports deep paths. If you don’t need this, you can enable lodash-webpack-plugin, which will remove this support:
72 KB → 772 B
// Before babel-plugin-lodash + lodash-webpack-plugin
import _ from 'lodash';
_.get({ a: { b: 5 } }, 'a.b');
// → returns 5
↓
// After babel-plugin-lodash + lodash-webpack-plugin
import _get from 'lodash/get';
_get({ a: { b: 5 } }, 'a.b');
// → returns undefined
Keep in mind, however, that you can’t just enable the plugin and leave it as-is. This plugin changes the Lodash functionality, so your existing code could break. Take a look at the list of features it removes by default.
Pitfall: duplicated Lodash#
There’re two common versions of Lodash: the lodash package and the lodash-es package (which is Lodash with ES exports). If you use the former package, and one of your dependencies uses the latter, you will find yourself having two Lodashes in a single bundle. To avoid this, alias lodash to lodash-es (or vice versa).
An example of a package that uses lodash-es is Redux.
Thanks to Valentin Semirulnik for this tip.
externals#
Sometimes you have a large project where some code is compiled with webpack and some code is not. Like a page with crosswords, where the crosswords module is built with webpack, and the site around it is not:
If both pieces of code have common dependencies, you can share the dependencies between them. This is done with the webpack’s externals option which lets you alias module imports to something different.
The common usage is when you have an instance of a library in the global object (like window), and you want to alias the library imports to this instance. In this case, you pass an object mapping the module names to the variable names:
// webpack.config.js
module.exports = {
externals: {
'react': 'React',
'react-dom': 'ReactDOM',
}
};
Webpack will replace all module references with variable references.
A less known approach is when the old code doesn’t put the libraries into the global object but loads them with an AMD-compatible loader. In this case, you can compile your webpack as an AMD bundle and alias modules to paths to the libraries:
// webpack.config.js
module.exports = {
output: { libraryTarget: 'amd' },
externals: {
'react': { amd: '/libraries/react.min.js' },
'react-dom': { amd: '/libraries/react-dom.min.js' },
}
};
Webpack will wrap your bundle into define() and make it depend on the libraries from externals:
// bundle.js
define(["/libraries/react.min.js", "/libraries/react-dom.min.js"], function () { … });
Then, the loader will load your libraries along with the bundle. The good thing here is that the libraries will be cached in the browser or in the loader cache – so they won’t be loaded twice.
Σ: Decrease front-end size#
- Configure minification
- Pass
NODE_ENV=production to the code
- Use ECMAScript imports and exports
- Drop unused locales in Moment.js
- Drop unused methods in Lodash
- Use
externals if you have common libraries
Task Improve caching#
Given: you have a front-end application. You want to cache it better so that the visitor loads it faster and doesn’t re-download the whole app when it’s updated.
Using hash#
The default approach of doing caching is to tell the browser cache a file for a very long time (e.g. a year), and rename the file when changing it to force browser to re-download it:
<!-- Before the change -->
<script src="./index.js?version=15">
<!-- After the change -->
<script src="./index.js?version=16">
Webpack also lets you do such thing. However, instead of versioning a file, it calculates the file hash which you can specify in the bundle name. In this case, each time you change the code, the file name will change, and the browser will re-download it:
// webpack.config.js
module.exports = {
entry: './index.js',
output: {
filename: 'bundle.[chunkhash].js'
// → bundle.8e0d62a03.js
}
};
The only remaining problem is how to get the file name to send it to the client. There are two solutions: HtmlWebpackPlugin and WebpackManifestPlugin.
HtmlWebpackPlugin is a more automated solution. During compilation, it generates an HTML file which includes all compiled resources. If your server logic is simple, then this plugin should be enough for you:
<!-- index.html -->
<!doctype html>
<!-- ... -->
<script src="bundle.8e0d62a03.js"></script>
WebpackManifestPlugin is a more flexible solution which is useful if you have a complex server part. It generates a JSON file with a mapping between file names without hash and file names with hash. You can use this JSON on your server:
{
"bundle.js": "bundle.8e0d62a03.js"
}
Pitfall: hash could change even if the bundle is the same#
The hash could change if you rename a file or compile the bundle under a different OS. This is a bug, and I was unable to find a workaround. You can see the discussion about the bug on GitHub.
Update: the previous version of this part recommended using webpack-chunk-hash as a solution. Turns out, it doesn’t help.
Code splitting#
The next way to improve caching is to split the bundle into smaller pieces.
Imagine you have a large website, and you’re compiling it into a single bundle:
Each time you’re changing a single module, the whole bundle gets recompiled. This means that even if you’re changing the comments module, and a specific user is only visiting the main page, they’ll still have to re-download the code for this page.
If you split your bundle into several pieces – one for the main page and one for the article page – the user will only have to re-download the changed piece of code. Webpack lets you do this. In webpack terminology, these pieces of the bundle are called chunks.
To split the code into chunks, you specify several entry points and do a few other changes. Here’s the optimal webpack config:
You specify multiple
entry points, and webpack generates a separate chunk for each point. Each chunk will only include the dependencies it needs
module.exports = {
entry: {
homepage: './index.js',
article: './article.js'
},
output: {
You replace a fixed filename with [name]. [name] will correspond to the entry point name
filename: '[name].[chunkhash].js'
},
plugins: [
new WebpackManifestPlugin(),
new WebpackChunkHash(),
You add two CommonsChunkPlugins. They let you move some code from existing chunks to new commons chunks.
The first plugin moves all node_modules dependencies to a separate chunk. This allows you update the code without invalidating dependencies.
The second plugin moves webpack’s runtime to a separate chunk. This allows you to update runtime without invalidating other code. Runtime is a webpack’s system code that is responsible for loading the app
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: m => m.context &&
m.context.includes('node_modules'),
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime',
minChunks: Infinity,
}),
You add ashedModuleIdsPlugin. By default, each module in webpack has an ID which corresponds to its order. If you add a new module, it can affect other module ids and invalidate the cached chunks. This plugin replaces order-based IDs with hash-based ones
new webpack.HashedModuleIdsPlugin(),
You add ChunkManifestPlugin.
By default, the webpack’s runtime contains a mapping between IDs of chunks and their names. If you configure the file name to contain the hash, as we did with the filename option, the hash will change with each file change, and so will the runtime.
ChunkManifestPlugin lets you extract this mapping into a separate JSON file. On the server, you’ll need to inline this file into the global webpackManifest variable
new ChunkManifestPlugin({
filename: 'chunk-manifest.json',
manifestVariable: 'webpackManifest'
})
]
};
With this config, webpack will generate 6 files:
Two separate entry points. Each should be loaded on the corresponding pages
homepage.a68cd93e1a43281ecaf0.js
article.d07a1a5e55dbd86d572b.js
File with vendor dependencies and file with webpack runtime
vendor.1ebfd76d9dbc95deaed0.js
runtime.d41d8cd98f00b204e980.js
Two manifest files that you’ll need on the server
manifest.json
chunk-manifest.json
And this is how often they’ll change:
homepage and article – when the app code in these modules changes,
vendor – when any dependencies of the app change,
runtime – when webpack’s runtime code changes (i.e. rarely and only with new webpack versions),
manifest.json – when you add a new chunk – but that doesn’t matter because this file is used in the server,
chunk-manifest.json – on any code change – but that doesn’t matter because this file is used in the server.
That’s a bit more files, but it lets you effectively leverage long-term caching.
On-demand code splitting#
The next way to improve caching (and optimize time to first paint) is to load some parts of code on demand.
Imagine you have a page with an article:
When opening this page, the visitor wants to see the content at first. Comments, sidebar and other parts of the page are less relevant to them. However, if you bundle all these blocks into a single file, the visitor will have to wait until the whole file is downloaded – with all the page modules. This isn’t cool.
Thankfully, webpack lets you optimize this by loading code on demand. You can specify that you want to load specific modules dynamically, and webpack will move them to separate chunks and download when they’re required. This is how it works:
You have an article-page.js file. When you compile it, the bundle receives all the code for articles, comments and sidebar
// article-page.js
import { renderArticle } from './components/article';
import { renderComments } from './components/comments';
import { renderSidebar } from './components/sidebar';
renderArticle();
renderComments();
renderSidebar();
↓
To load code on demand, you replace static import with dynamic import() calls. Webpack will move the code from ./comments.js and ./sidebar.js into separate chunks and load them when they’re required
// article-page.js
import { renderArticle } from './components/article';
renderArticle();
import('./comments.js')
.then((module) => { module.renderComments(); });
import('./sidebar.js')
.then((module) => { module.renderSidebar(); });
This change will improve the initial loading performance. Also, it will optimize caching because when you change the code that belongs to a specific chunk, other chunks won’t get affected.
The only thing left is to add chunk hashes to their names. This is done with output.chunkFilename option. This option is specific to chunks generated by on-demand code splitting:
// webpack.config.js
module.exports = {
output: {
filename: '[name].[chunkhash].js',
chunkFilename: '[name].[chunkhash].js',
}
};
Pitfall: Compiling with Babel#
If you compile this code with Babel with default presets, you’ll have a syntax error: Babel don’t understand import() out of the box. To prevent the error, add the syntax-dynamic-import plugin.
Other solutions#
There are a couple of other solutions that I haven’t worked with but which should also bring benefits with caching:
AggressiveSplittingPlugin is a plugin that optimizes your code for HTTP/2 by splitting each chunk into smaller chunks as much as possible. This greatly improves caching on the client side but slightly worsens the gzip compression. See the example in the webpack repository.
OfflinePlugin is a plugin that’s usually used for creating offline-ready apps. However, you can use it to improve caching too! The plugin generates a service worker that downloads all the site resources in the background. So when a visitor visits the site and then switches to a different page, they’ll have all the necessary files already cached. See the OfflinePlugin docs.
Σ: Improve caching#
- Add hash to the name of your resources and make the server tell clients to cache the resources for a long time
- Split your code into smaller chunks with different entries, on-demand code splitting and
AggressiveSplittingPlugin
- Try caching your resources in the background with
OfflinePlugin
The next part of the guide, “Speeding up build and improving the development workflow”, is coming soon. Leave your email to know when it’s out:
(you’ll receive an email about the next part of the guide + a couple of more webpack-related posts if I write them; no spam)
 Short basics of caching
Short basics of caching