From 2017 to 2023, I worked as a self-employed web performance consultant. I was lucky to do some cool stuff (work with Google and another company every American knows, help many hot startups, speak at worldwide conferences). In 2024, I turned that page and became an employee at Framer, to lead web performance efforts with a great team of engineers.
Here are some things I learned over these six years.
Contents:
- Career
- Money
- Personal
- What’s next
Career#
How to negotiate (salaries and job titles)#
At my first job, my relationship with money was one of avoidance. Sure, I wanted to earn more, but saying that to my manager out loud, or actively negotiating a raise somehow felt “sinful”. Great engineers are motivated by challenges, not by money, right? You should focus on growth, and money and status will follow automatically, right??
Then, I jumped into consulting and had to learn how to sell my services. After doing sales for a while, I’m strongly convinced my earlier beliefs were anti-productive.
You vs. company. It is good to be motivated by challenges and focus on growth. But if you don’t also actively negotiate for money, you’ll lose out.
The reality is, your company does negotiate. It’s a business, so negotiating for better conditions – with suppliers, but also with employees – is literally one of its primary activities. Your company is interested in paying you well to retain you (because hiring a new candidate is even more expensive), but if you never negotiate, they’ll have no reason to pay you more than that. Not because they are bad, or hate you, or don’t value you enough, but simply because they are capitalists.
Also, negotiating isn’t sinful! Negotiating (salaries and titles) is one of the primary job responsibilities of your manager. They wouldn’t think of you less if you push back on the offer and ask for more money – on the contrary, some people might actually respect you more! “Oh, he’s got experience.”
Proof of value. To negotiate about salary and title, it helps to know what value you’re bringing to the company. The way I approach this is by having a “Brag Document”:
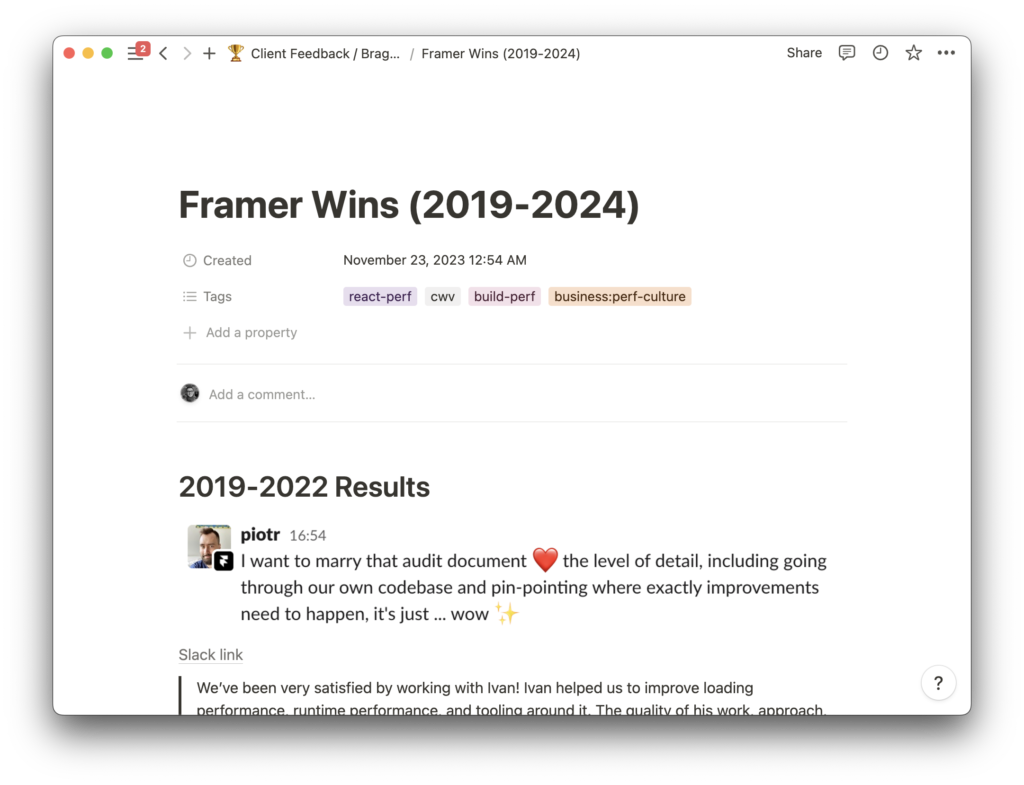
Every time I do something that results in a clear win, gets praised by somebody else, or exceeds my job responsibilities, I save a link or a screenshot of that into a Notion document. This helps both to build the portfolio (when you’re self-employed), to write self-reviews during quarterly feedback (when you’re employed), and to pick the best examples of your value when you’re approaching your manager for negotiations.
Fear. Negotiations are, of course, very scary. What helps is knowing you have options – that is, if you request a new title or a higher salary, and the company says “no”, you can do something else apart from just accepting that “no”.
In self-employment, having options comes naturally. If you have a lot of incoming projects, you can freely experiment with prices and negotiate. If you don’t have a lot of projects, and money isn’t good, you can always go back to employment.
In employment, this is harder. But know this: if your company has a good culture, failing at negotiations won’t get you punished. If you ask your manager for a raise, and they refuse, they won’t automatically fire you or think of you worse. Instead, a good manager will either
- propose a way for you to reach what you’re asking for (e.g., through a growth plan), or
- tell you right away that you won’t be able to reach that salary or title in the company.
This means that as long as your company has a good culture, the worst outcome of salary negotiations would be “nothing changes”. Which isn’t that bad! If you don’t try to negotiate, nothing will change anyway.
(See also “Money” below for more money-focused learnings.)
Write more#
Writing is probably responsible for some of the best outcomes in my career. A webpack performance guide landed me a contract with Google. My web performance blog, Twitter, and Telegram channel were responsible for 2/3rds of the new clients I was getting when consulting. A Twitter thread with web performance tips got me invited to speak at the Smashing Conference.
In general, writing sets you apart from most other engineers. It shows your skills better than an interview. It attracts like-minded people, which increases your career opportunities. The only drawback about it – for me – is that it’s annoyingly slow.
I don’t have great tips for writing, apart from “just try it” (quality comes with practice) and “don’t be afraid that you’ll write badly and be judged” (if one of your blog posts is bad, people will generally just ignore it instead of judging it) and “have some basic form to convert people into subscribers” (otherwise you fail to capture a lot of value from your writing). If you aren’t sure what to write about, think of what you learned this week – and make a short blog post summarizing that. And finally, once you’ve got a grip on writing, see “Making You Writing Work Harder For You” from, again, Patrick McKenzie.
You can pull levers you didn’t know you could#
“Agency” is hard to define, but I’ll try. “Low agency” is when you mostly wait for other people to fix things. “High agency” is when you want something, and you pursue it yourself. Agency is a spectrum, and different people are at different points on that spectrum.
Being self-employed grows your agency a lot. Suddenly, you realize that a lot of things that you always perceived as an unchangeable norm are actually just a result of some human agreements. Which means you don’t have to always follow them! This starts with a simple “I can renegotiate working Mon-Fri” and spreads to deeper “this process feels annoyingly broken, but I can just try and fix it?” or “if nobody in the company has ever tried shadowing the CEO but I want to, I can just ask.”
See also: “Things You’re Allowed To Do.”
Money#
Your beliefs might be the main bottleneck#
My income in 2017 (when I first started consulting) was $24,000/year – a decent one for a new senior engineer in Belarus. By the end of my consulting experience, it reached a solid Bay Area engineer’s level.
Every time it substantially increased, however, I was genuinely surprised: “Wait, people pay me that?”
- In 2017, when I just started consulting, I set my initial hourly rate to $30 (double what I was making as an employee). A friend of mine tried to convince me to up it to $90/hr instead. That didn’t work out right away, but that allowed me to stabilize it at $60/hr for a couple of years, earning 2× more of what I was expecting to get initially.
- In 2021, whenever I’d run a web performance audit, I’d usually charge a client $5,000, budget a week for the audit, and then accidentally end up spending two instead. When I got fed up with regularly exceeding my own budgets, I bumped the audit price from $5,000 to $10,000. Surprisingly, that just worked. The customers kept happily paying twice more for the same audit (it was still valuable for them!), and I doubled my income.
My lessons from all those bumps that happened over the years were: there’s easily more money to be earned than I think I could earn.
The “I think” bit is crucial. When you’re a software engineer employed in Belarus, most people around you are also software engineers employed in Belarus. You might see your friends get paid $30,000/yr or $50,000/yr. You might see paths to reach that income. But nobody in your environment earns $200,000/yr or $400,000/yr, so it’s very hard to tangibly feel “wow, I can do the same” – even though, in tech, you definitely can. Your own beliefs are your biggest roadblock.
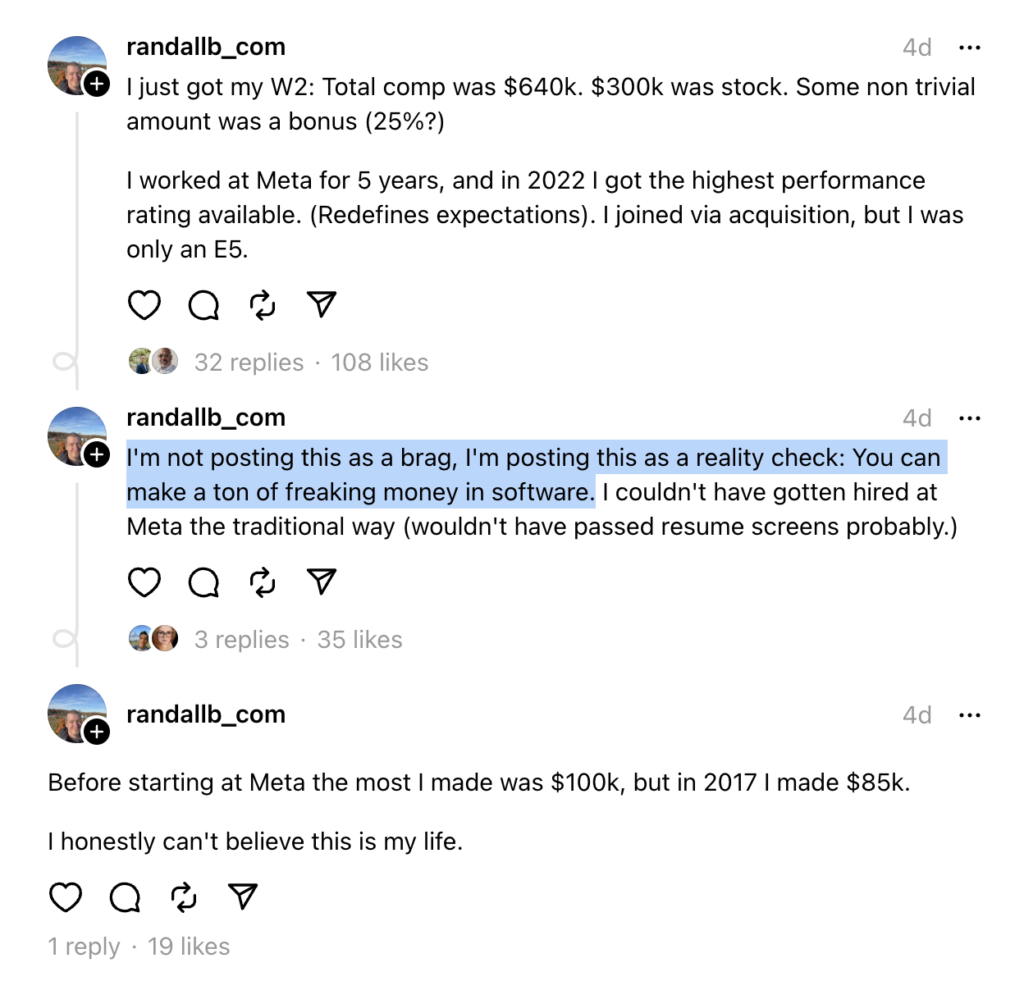
What helped me on my income path was bumping into people who were earning more than me – and asking them to help me with reaching their level. In 2017, it was my friend Gosha who pushed me to become self-employed. In 2021, it was a group of entrepreneurship-focused friends who convinced me to increase the audit prices. I’m forever grateful to those folks.
I don’t want this section to end with “well just be lucky at bumping into the right people lol.” Building good connections is hard, and I’m still struggling with that, having moved to a new country two years ago. However, you can build these connections intentionally! (Spencer Fry has a great article on how to network better.) And if you encounter me at some conference, I’d be glad to try and help in the same way I was helped before.
How to earn more#
Apart from realizing “I can earn more”, it also helps to know how to do that.
My favorite income advice on the internet comes from Patrick McKenzie. If you’re employed, here’s his (extremely popular and well-written) article about salary negotiations. If you’re self-employed, here’s another one with great advice.
And in my consulting life, what helped the most was switching from hourly to project-based pricing and investing in a portfolio of cases.
Hourly → project pricing. Hourly pricing is easy to start with, but at some point, it turns from a benefit to a liability. It’s hard to scale: not only because to earn more, you need to put in more hours, but also because hourly pricing has anchoring. No matter how great a consultant you are, you’ll have a very challenging time invoicing a client $300/hour. Most software engineers whom the client would usually encounter would charge the client $80-150/hr. Even if you’re an incredible engineer, you’d have a very hard time convincing the client you’re worth 2-4 times more than an average engineer does.
The solution here is to not charge per hour. Instead, switch to charging per project. “Project” is a unique deliverable, which means a client can’t easily compare it to anything else, which means that instead of thinking “why is that consultant charging me those insane rates”, the client will be forced to think in terms of “is this project valuable enough for me”. And this gives you much more leeway! It’s hard to invoice $300/hour, but it’s much easier to invoice $6,000 for a 20-hour project if that project helped the client to earn much more than $6,000.
Dan Mall covers how to design project prices in his book.
Building a portfolio. Patrick McKenzie advocates for writing a case study after every successful project. I’m writing too slowly to do that; but still, after every project, I’d normally have a dialog that would go like this:
Me: “Hey, by the way, now that this project is over – could you let me know if you’re satisfied, more than satisfied, almost satisfied, or not really satisfied with the results?”
Client: “Hey – I’m [satisfied / very satisfied]! X was amazing, and Y was great.”
Me: “Oh thank you so much for the feedback! Would you mind if I quote what you said about X and Y for my portfolio?”
This would allow me both to collect feedback about what worked and didn’t work well; and to repurpose that feedback for testimonials. Asking a client to write a testimonial for you is rarely successful – the client has like a thousand more important things to do before that. But taking their feedback, drafting a testimonial based on that, and getting an “okay” from them works much better.
Personal#
Having infinite money might change you for the worse#
In 2021, I had “infinite” money. I lived in Belarus, where the median salary is $600/mo, I was earning a Bay Area-level income, and I was paying a 3% tax on that income. I spent a lot, but I was still earning faster than I could spend.
That was a conflicting experience. During that year, I felt rich and confident. I tried luxuries – chic hotels, fancy jewelry – that I thought I’d never be able to experience. Unfortunately, my feeling of self-importance also grew, and I got snobbier. I started feeling that I’m better than others, which was noticeable, especially to my friends and family. I ignored their feedback.
Most of these changes, luckily, got reverted when I moved from Belarus to the Netherlands, and my income and taxes got much more aligned with what other people were earning. It took me a few months to notice and undo the personality changes, and another year to get rid of most overly expensive habits.
I’m still trying to figure out what lessons to take from this experience, however.
My biggest learning so far, I think, is that I can’t always trust my gut to guide me. “Do I feel right about this?” is one of the primary decision-making approaches I use, alongside the regret minimization framework. The challenge is that during that year, my gut didn’t feel wrong at all! Neither when I was choosing to act pretentious nor when my friends were telling me I’d changed.
My second biggest learning is that there isn’t that much value in being rich. It’s nice, of course, and if I ever get rich again, I’d probably enjoy it. But I feel I understand both the gains (feelings of prestige, access to nice luxuries, life that’s easier in some aspects) and the costs (more work, fewer people who I can be vulnerable with, perhaps similar personality changes again) much better now. And at this point, I’m not feeling like paying them again.
Burnout is hard to notice#
In 2023, I was actively burning out. I was getting bored with repetitive projects; I was pushing myself to earn more, but to no avail; and I was struggling to make my consulting schedule work with other obligations I had.
This, luckily, was resolved when I joined Framer; I’m in a much better place now. But what that experience taught me is:
When you’ve been feeling bad for a while (burning out, depressed, or similar), you mostly forget how you felt before. You tell yourself, “Well, I’m feeling a little meh about my work, but I guess it’s always been like this.” You tell yourself, “A lot of people feel meh about their work, it’s normal and expected.” And you don’t act on this “meh” feeling in any way. This is a trap.
What you actually need to do if you’re feeling “meh” is to look back. Have you been feeling this “meh” for more than six months? Something is definitely off, this isn’t how most people feel at the baseline. Have you been trying to fix that “meh” for a while? Your approach to fixing that obviously isn’t working. Try something else.
What helped me was raising these feelings of “meh” with an experienced manager friend of mine – and, through conversations with her, realizing that I might’ve outgrown the goals I had. Once that happened, it became clear what I needed to change.
Confidence comes from being at peace with yourself#
For the past three years, whenever I’d see any consulting agency site with a heading like this, I’d shrink inside:

You could never make me write a paragraph starting with “Here’s why PerfPerfPerf [Ivan’s consulting agency] is the best.” Not because my work wasn’t good – I was regularly delivering 2-4× React performance improvements for my clients – but because the thought of writing this would instantly drown me in anxiety. Am I actually the best consultant? Don’t I suck at X, Y, Z?
This is a confidence issue. Surprisingly, what I learned about confidence, from my experience and from that of others, is that previous achievements barely help with it. You can rely on them to feel more confident, but no matter how many successes you had, a single failure is often enough to bring the anxiety back in.
It turns out that what actually helps with confidence is being at peace with yourself, aligning your outer self (how you act and present yourself to others) with your inner self (how you actually feel on the inside). I’m not sure why that works. But what I found is when I’m kinder to myself, when I allow myself to be my genuine self – I feel calmer, more relaxed, and more confident, both in who I am and the decisions I make.
Now, how do you get at peace with yourself? Some people get a lot of help from meditation. Some benefit from mentorship. Some do therapy and take drugs. For me, what seems to help the most is being in a secure, trusting relationship where I feel loved and genuinely accepted for who I am. This is still a bit of a crutch – when I rely on relationships to feel accepted, I’m borrowing that acceptance from the outside instead of actually producing it inside. But as time goes on, I’m getting better and better at the latter as well.
What’s next#
I achieved the best thing a modern human can achieve:

Now that I’m at Framer, for the first time in years, I’m going to work not alone – but in a team of incredibly talented engineers, and on projects I’m very motivated about. I’m very excited about this. Let’s see how it goes.
Thank you to Giulio, Jacob, and Stefan for reviewing earlier drafts of this post.